import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.TimeoutException;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
public class Selenium {
public static void main(String[] args) {
try {
String URL = "https://www.tistory.com/category/life";
runSelenium(URL);
} catch ( Exception e ) {
e.printStackTrace();
}
}
private static void runSelenium(String URL) throws Exception {
System.out.println("#### START ####");
// 1. WebDriver 경로 설정
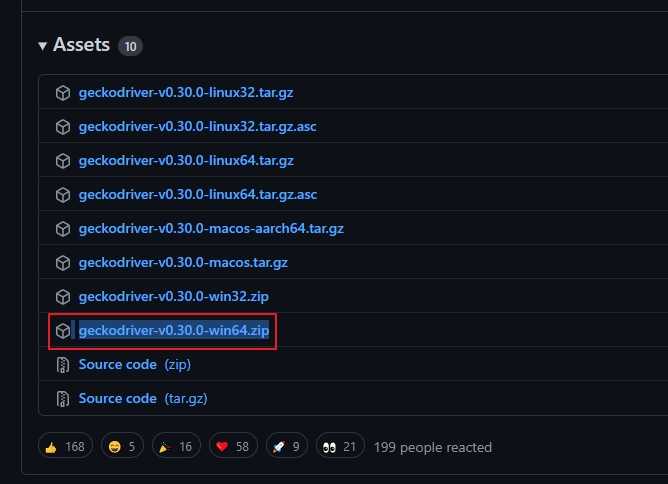
Path path = Paths.get("C:\\java/driver/geckodriver.exe");
System.setProperty("webdriver.gecko.driver", path.toString());
// 2. WebDriver 옵션 설정
FirefoxOptions options = new FirefoxOptions();
options.addArguments("--start-maximized"); // 최대크기로
options.addArguments("--headless"); // Browser를 띄우지 않음
options.addArguments("--disable-gpu"); // GPU를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--no-sandbox"); // Sandbox 프로세스를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--disable-popup-blocking"); // 팝업 무시
options.addArguments("--disable-default-apps"); // 기본앱 사용안함
// 3. WebDriver 객체 생성
WebDriver driver = new FirefoxDriver( options );
try {
// 4. 웹페이지 요청
driver.get(URL);
// 5. 페이지 로딩을 위한 최대 5초 대기
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
// 6. 조회, 로드될 때까지 최대 10초 대기
WebDriverWait wait = new WebDriverWait(driver, 10);
String byFunKey = "CSSSELECTOR";
String selectString = "div#mArticle";
// String byFunKey = "XPATH";
// String selectString = "//*[@id=\"mArticle\"]/div[2]/ul/li[3]/a";
WebElement parent = wait.until(ExpectedConditions.presenceOfElementLocated(
byFunKey.equals("XPATH") ? By.xpath(selectString) : By.cssSelector(selectString) ));
// System.out.println("#### innerHTML : \n" + parent.getAttribute("innerHTML"));
// 7. 콘텐츠 조회
List<WebElement> bestContests = parent.findElements(By.cssSelector("div.section_best > ul > li > a"));
System.out.println( "best 콘텐츠 수 : " + bestContests.size() );
if (bestContests.size() > 0) {
for (WebElement best : bestContests) {
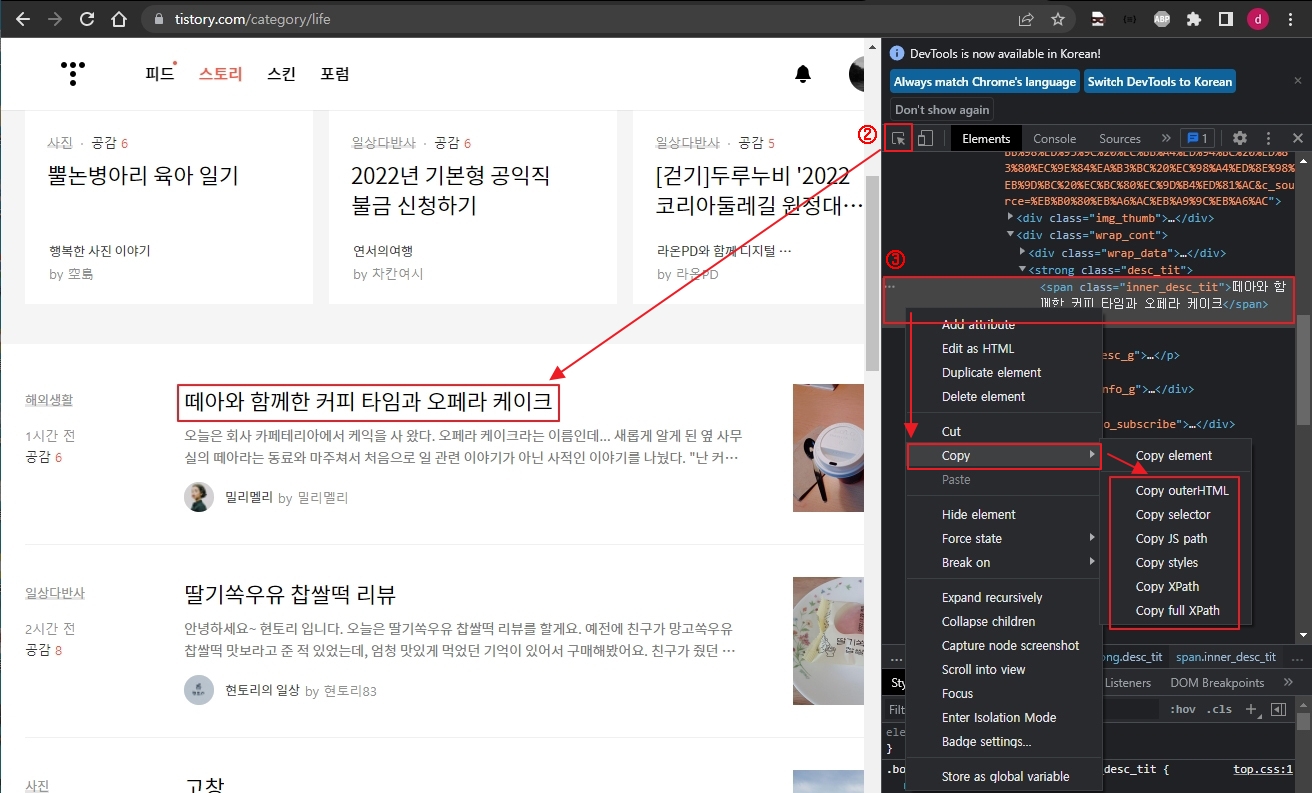
String title = best.findElement(By.cssSelector("div.wrap_cont > strong > span")).getText();
String name = best.findElement(By.cssSelector("div.info_g > span.txt_id")).getText();
System.out.println("Best title / blog name : " + title + " / " + name);
System.out.println("Best url : " + best.getAttribute("href"));
System.out.println();
}
}
System.out.println("########################################");
List<WebElement> contents = parent.findElements(By.cssSelector("div.section_list > ul > li > a"));
System.out.println( "조회된 콘텐츠 수 : " + contents.size() );
if( contents.size() > 0 ) {
for(WebElement content : contents ) {
String title = content.findElement(By.cssSelector("div.wrap_cont > strong > span")).getText();
String name = content.findElement(By.cssSelector("div.info_g > span.txt_id")).getText();
System.out.println("콘텐츠 title / blog name : " + title + " / " + name);
System.out.println("콘텐츠 url : " + content.getAttribute("href"));
System.out.println();
}
}
} catch ( TimeoutException e ) {
e.printStackTrace();
System.out.println(e.toString());
} catch ( Exception e ) {
e.printStackTrace();
System.out.println(e.toString());
}
// 8. WebDriver 종료
driver.quit();
System.out.println("#### END ####");
}
}